
Reinforcement Learning: Maze Games and OpenAI Gymnasium
OpenAI’s Gymnasium: Balancing Cart Pole Agent
The goal of this coursework is to train an agent to balance a pole attached (by a frictionless joint) to a moving (fric- tionless) cart by applying a fixed force to the cart in either the left or right direction. The coursework uses OpenAI’s Gymnasium Cart Pole Environment [1].
The aim is to train a Deep Q-Learning Agent (DQN) to keep the pole balanced (upright) for as many steps as possible by only controlling the direction of the force applied to the pole.
Hyperparameter Tuning Strategy
| Hyperparameter | Value |
|---|---|
| Hidden Layer Size | 5 |
| Number of hidden Layers | 2 |
| Learning Rate | 0.01 with adaptive learning |
| Replay Buffer Size | 30000 |
| Number of Training Episodes | 3000 |
| $\epsilon$ (for $\epsilon$-greedy policy) | 0.2 with $\epsilon$-decay |
| Reward Discount | 1 |
| Batch size for RB sampled trace | 100 |
| Target Network Update Frequency | 50 |
| Decay Rate for $\epsilon$-greedy policy | 0.95 |
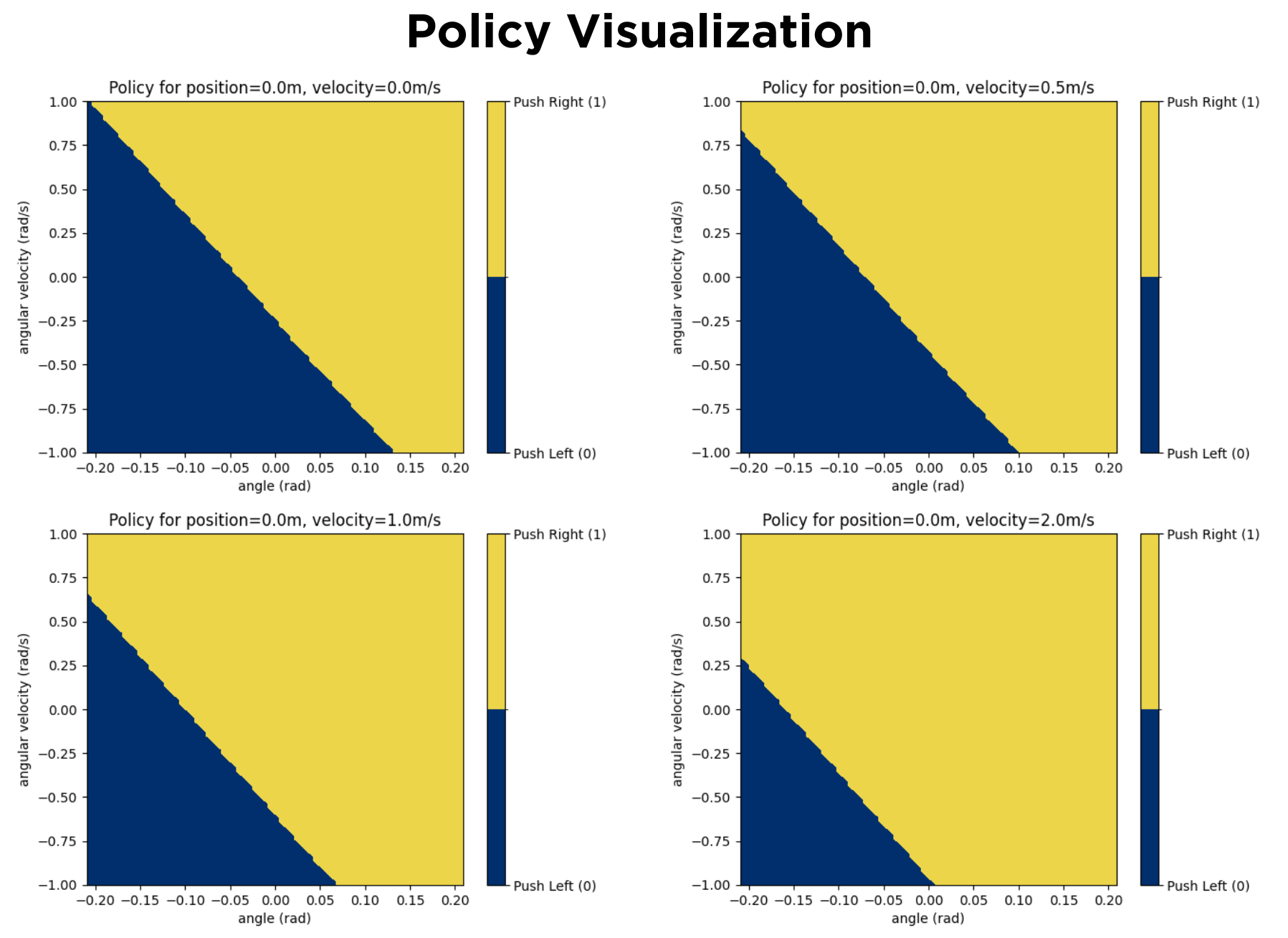
An overview of the found optimal policy is shown below:
Maze Game
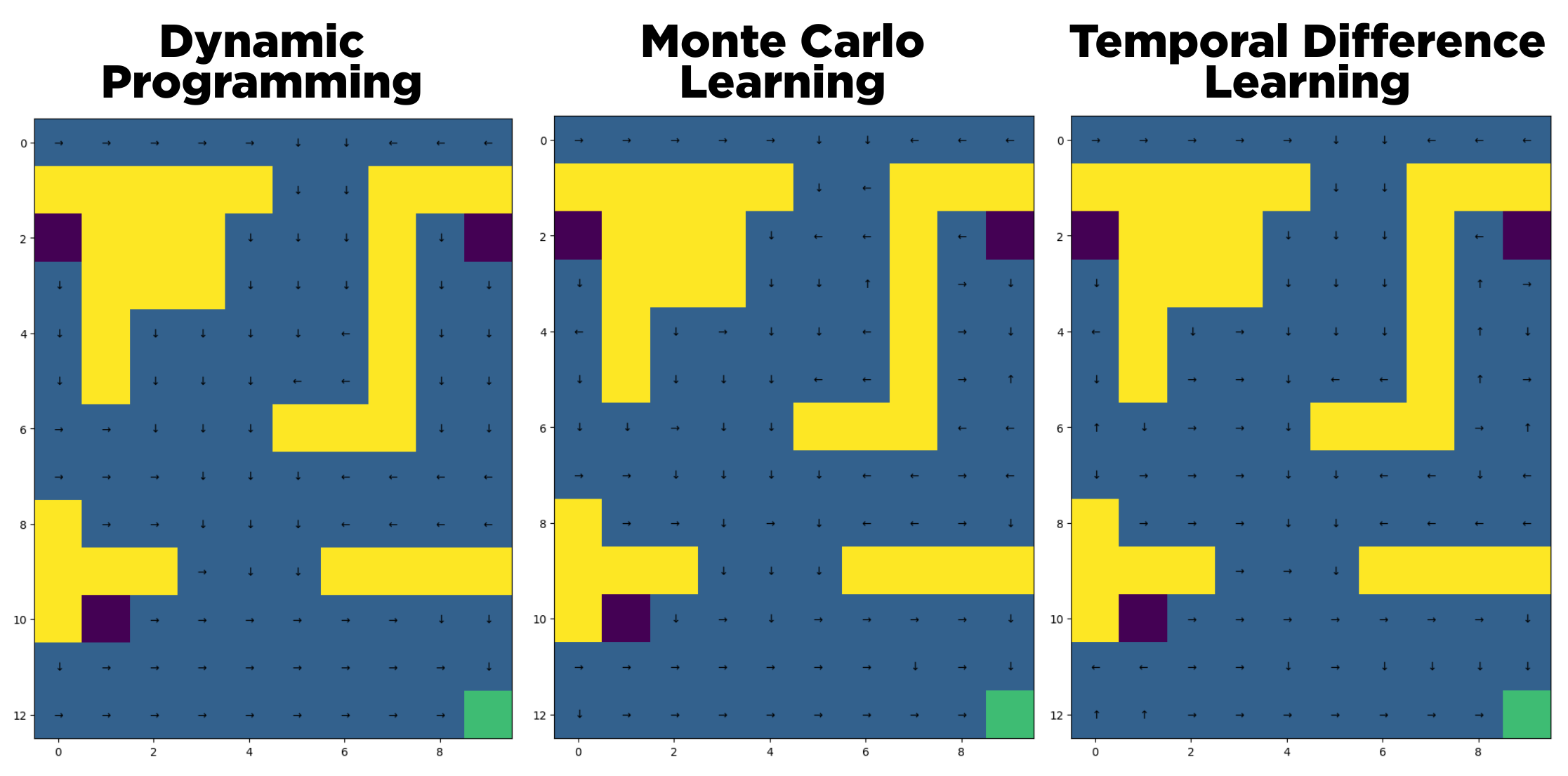
This Coursework’s goal is to solve a Maze environment modelled as a Markov Decision Process (MDP) using RL techniques that do not require full knowledge of the dynamic of the environment: Monte Carlo and Temporal Difference learning. In the maze, yellow squares symbolise obstacles, and the dark/purple and green squares absorbing states, that correspond to specific rewards. Absorbing states are terminal states, there is no transition from an absorbing state to any other state.
Optimal policies found using different methods are shown below:
References
[1] OpenAI (n.d.). OpenAI’s Gymnasium: Cart Pole Environment. [online] gymnasium.farama.org. Available at: https://gymnasium.farama.org/environments/classic_control/cart_pole/