
Patronizing and Condescending Language Recognition with Language Models
Patronizing and Condescending Language (PCL) is a type of hate speech that targets vulnerable communities, without explicitly including hateful words. Due to the complexity and subtleness of human expressions, PCL detection represents a challenging sentiment analysis task [1]. The SemEval 2022 Don’t Patronize Me! Task [2] showed, however, that powerful language models like transformer-based models can identify PCL with a high level of accuracy. Our Project compares the performance, strengths and faults of three separate models, Support Vector Machine (SVM), Bidirectional LSTM (BiLSTM) and a BERT-based transformer model (RoBERTa), on the original SemEval-2022 data, consisting of over 10 thousand paragraphs associated with vulnerable social groups.
Model
Our final approach leverages a RoBERTa-based Transformer architecture. By training more, and removing the next-sentence prediction objective, RoBERTa expands upon BERT and captures richer contextual clues, spotting subtle patronization. We fine-tuned the baseline SemEval RoBERTa model because of its strong performance in the Task, and how its self-attention mechanism helps capturing contextual word interactions.
To enhance performance, we performed:
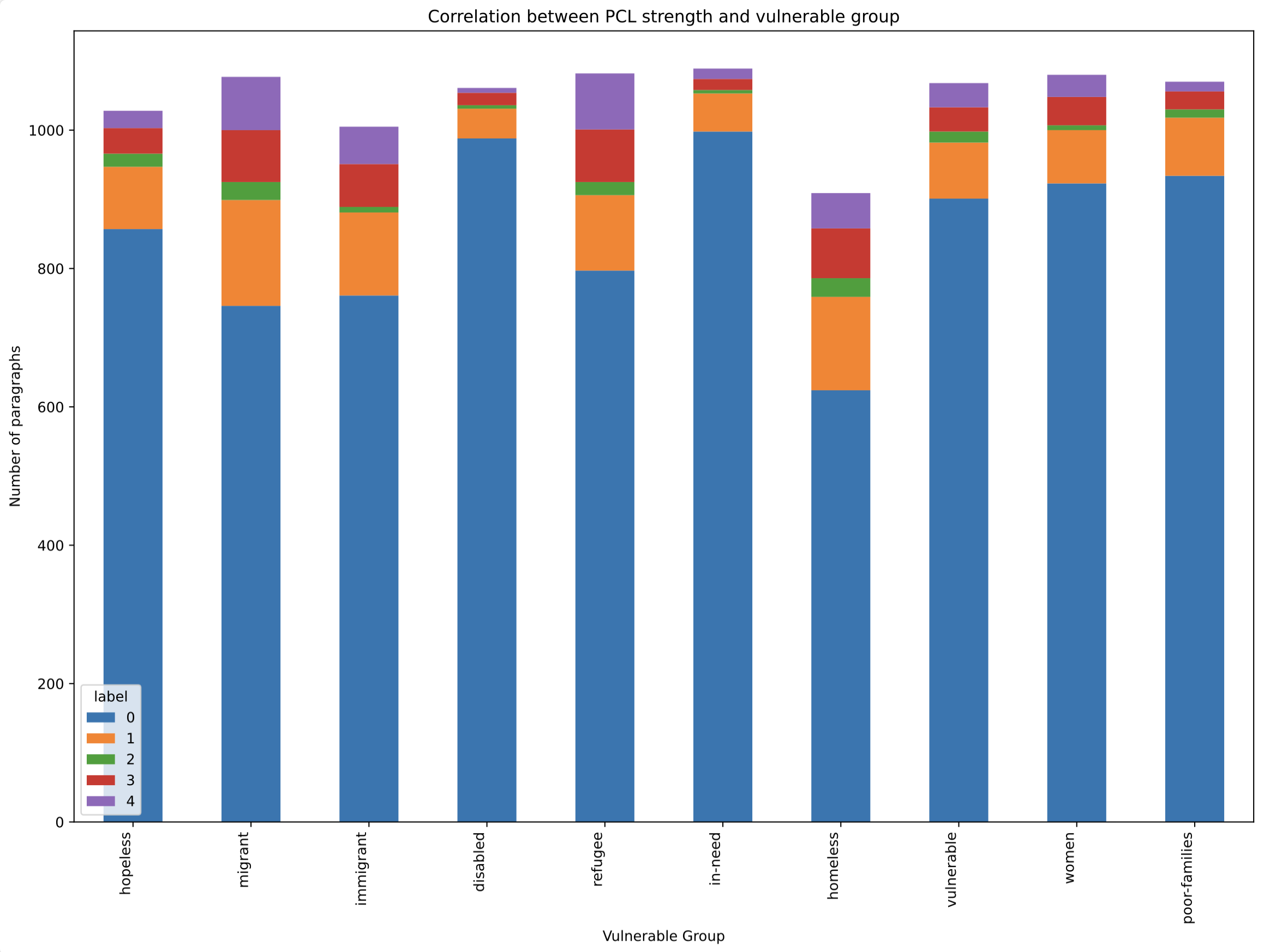
- Data Preprocessing: the community keyword, such as “women” or “refugee”, is appended to the beginning of each training example.
- Downsampling: we used downsampling to achieve a 1:3 ratio of positive (PCL) to negative (non-PCL) examples, to counter the dataset’s imbalance (where only a minority of paragraphs contain PCL)
- Synonym Replacement via WordNet: used to replace 10% of tokens with randomly sampled synonyms, to introduce lexical variety.
- Backtranslation using MarianMT: implemented to translate a random subset of 20% of paragraphs from English to German and back to English. This technique can paraphrase sentence structure and introduce additional lexical variety.
Findings
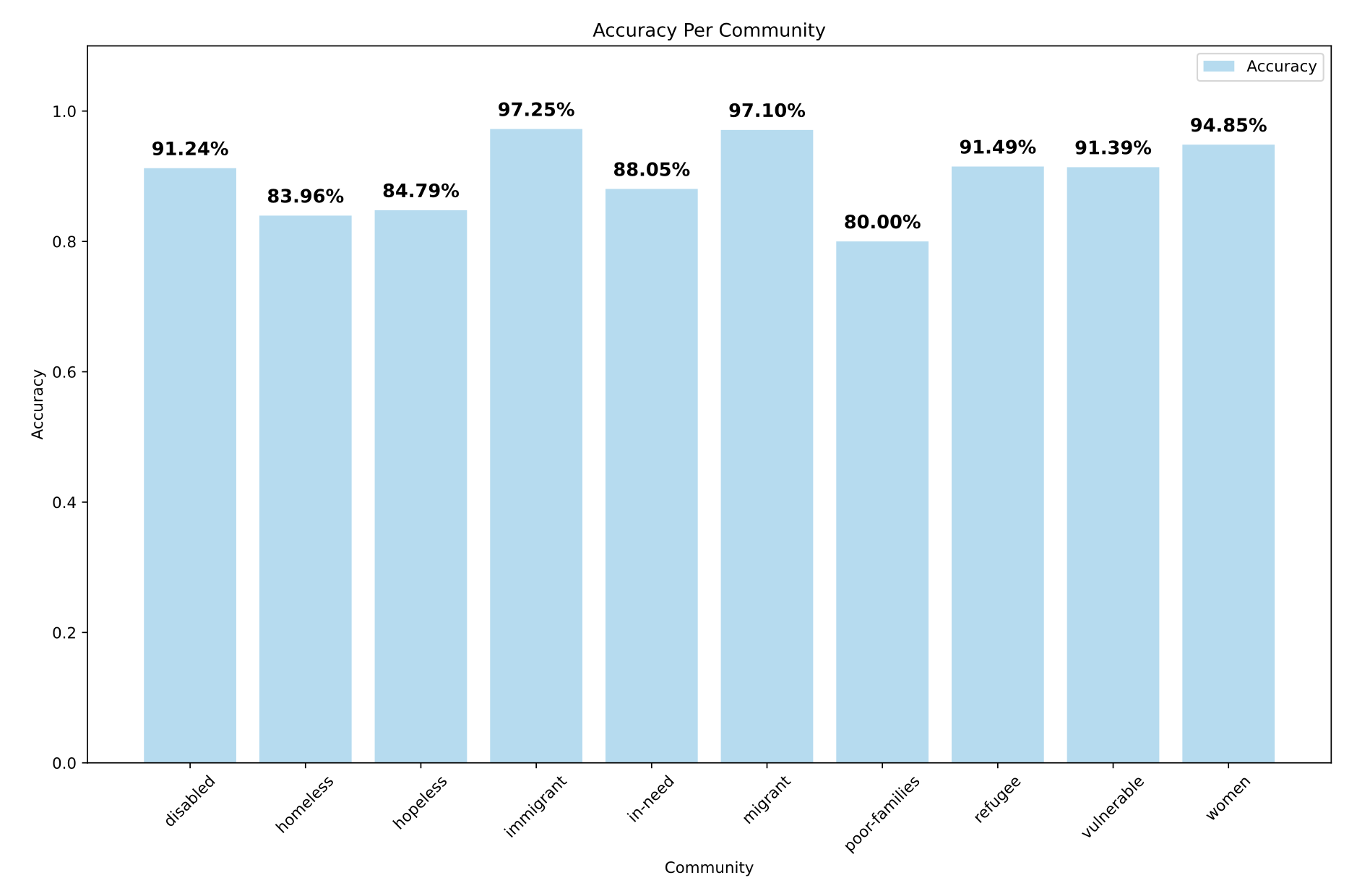
Our final model achieved a F1 score of 0.57, increasing the baseline SemEval F1 score on the official Dev Set by +0.9. We found that longer paragraphs and borderline PCL examples posed the most difficulty for the classifier, while extremely high or zero PCL texts were easier to predict. We observed that performance varies by data category.
References
[1] Carla Perez-Almendros and Steven Schockaert. 2022. Identifying condescending language: A tale of two distinct phenomena? Unpublished
[2] Carla Perez Almendros, Luis Espinosa Anke, and Steven Schockaert. 2020. Don‘t patronize me! anannotated dataset with patronizing and condescending language towards vulnerable communities. In Proceedings of the 28th International Conference on Computational Linguistics, pages 5891–5902, Barcelona, Spain (Online). International Committee on Computational Linguistics.